

What is data mining?
Data mining is a process used by companies to turn raw data into useful information. By using software to look for patterns in large batches of data, businesses can learn more about their customers to develop more effective marketing strategies, increase sales and decrease costs. Data mining depends on effective data collection, warehousing, and computer processing.
.jpg)
Why is data mining important?
So why is data mining important? You’ve seen the staggering numbers – the volume of data produced is doubling every two years. Unstructured data alone makes up 90 percent of the digital universe. But more information does not necessarily mean more knowledge.
Data mining allows you to:
- Sift through all the chaotic and repetitive noise in your data.
- Understand what is relevant and then make good use of that information to assess likely outcomes.
- Accelerate the pace of making informed decisions.
How does data mining work?
The data mining process involves a number of steps from data collection to visualization to extract valuable information from large data sets. As mentioned above, data mining techniques are used to generate descriptions and predictions about a target data set. Data scientists describe data through their observations of patterns, associations, and correlations. They also classify and cluster data through classification and regression methods, and identify outliers for use cases, like spam detection.
Data mining usually consists of four main steps: setting objectives, data gathering and preparation, applying data mining algorithms, and evaluating results.
1. Set the business objectives
This can be the hardest part of the data mining process, and many organizations spend too little time on this important step. Data scientists and business stakeholders need to work together to define the business problem, which helps inform the data questions and parameters for a given project. Analysts may also need to do additional research to understand the business context appropriately.
2. Data preparation
Once the scope of the problem is defined, it is easier for data scientists to identify which set of data will help answer the pertinent questions to the business. Once they collect the relevant data, the data will be cleaned, removing any noise, such as duplicates, missing values, and outliers. Depending on the dataset, an additional step may be taken to reduce the number of dimensions as too many features can slow down any subsequent computation. Data scientists will look to retain the most important predictors to ensure optimal accuracy within any models.
3. Model building and pattern mining
Depending on the type of analysis, data scientists may investigate any interesting data relationships, such as sequential patterns, association rules, or correlations. While high frequency patterns have broader applications, sometimes the deviations in the data can be more interesting, highlighting areas of potential fraud.
Deep learning algorithms may also be applied to classify or cluster a data set depending on the available data. If the input data is labelled (i.e. supervised learning), a classification model may be used to categorize data, or alternatively, a regression may be applied to predict the likelihood of a particular assignment. If the dataset isn’t labelled (i.e. unsupervised learning), the individual data points in the training set are compared with one another to discover underlying similarities, clustering them based on those characteristics.
4. Evaluation of results and implementation of knowledge
Once the data is aggregated, the results need to be evaluated and interpreted. When finalizing results, they should be valid, novel, useful, and understandable. When this criteria is met, organizations can use this knowledge to implement new strategies, achieving their intended objectives.
What are the applications of data mining?
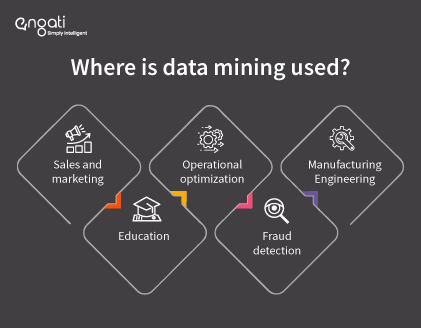
Data mining techniques are widely adopted among business intelligence and data analytics teams, helping them extract knowledge for their organization and industry. Some data mining use cases include:
1. Sales and marketing
Companies collect a massive amount of data about their customers and prospects. By observing consumer demographics and online user behavior, companies can use data to optimize their marketing campaigns, improving segmentation, cross-sell offers, and customer loyalty programs, yielding higher ROI on marketing efforts. Predictive analyses can also help teams to set expectations with their stakeholders, providing yield estimates from any increases or decreases in marketing investment. Data mining is also widely used in customer relationship management (CRM). The company can collect and analyze customer data so that rather than being confused about what to focus on, they can get filtered results and concentrate on the right initiatives in order to improve customer retention.
2. Education
Educational institutions have started to collect data to understand their student populations as well as which environments are conducive to success. As courses continue to transfer to online platforms, they can use a variety of dimensions and metrics to observe and evaluate performance, such as keystroke, student profiles, classes, universities, time spent, etc.
3. Operational optimization
Process mining leverages data mining techniques to reduce costs across operational functions, enabling organizations to run more efficiently. This practice has helped to identify costly bottlenecks and improve decision-making among business leaders.
4. Fraud detection
While frequently occurring patterns in data can provide teams with valuable insight, observing data anomalies is also beneficial, assisting companies in detecting fraud. While this is a well-known use case within banking and other financial institutions, SaaS-based companies have also started to adopt these practices to eliminate fake user accounts from their datasets.
5. Manufacturing Engineering
Data mining tools can be used to identify patterns in complex manufacturing processes. Data mining can be utilized in for the purpose of extracting the relationships between product architecture, product portfolio, and customer needs data. You can also use data mining to predict the product development span time, cost, as well as dependencies among other tasks.




.jpg)















